This project was completed during my fifth week at Metis data science bootcamp. The learning objectives for this project were building a supervised learning (classification) model and deploying its product on a web app. I chose a topic that was dear to me, the obesity pandemic in the US.
According to the CDC, obesity-related diseases are the leading causes of death in the United States. People who are obese have higher chances of developing heart disease, hypertension, stroke, and even (some) cancers. With these statistics, I wondered: How much is the rise of obesity-related diseases influenced by our lifestyle? How does our (seemingly harmless) habit of snacking or dining out affect our chances of becoming obese? What is the impact of physical exercise, or its lack thereof, on our weight and overall health?
Data acquisition and pre-processing
To assess the health impacts of eating and exercise habits, I decided to build a classification model that is trained on a subset of American Time Use Survey (ATUS) Eating & Health Module Microdata Files, collected by the Bureau of Labor Statistics (also featured in Kaggle).
This dataset represents multi-year surveys that were conducted from 2006 to 2008 and from 2014 to 2016; It contains ~11,000 observations with 39 topics/questions related to weekly eating habits and other lifestyle choices. I chose body mass index (BMI) as the TARGET value to predict. According to CDC, people with BMI>30 are classified as obese, whereas others with BMI<30 are considered not obese. The ratio of obese and not obese was 72%:28%, an imbalanced class situation.
Splitting the dataset. I split the dataset into training (80%) and testing (20%) sets for model learning and evaluation, respectively. To reflect the ‘original’ imbalance scenario, I split the data using sklearn’s stratification feature. Then, I used random-oversampling (ROS) method from imblearn to obtain a balanced training set of obese and not obese classes, i.e., ~6,000 observations of each class.
Of the 39 survey questions, I decided to use five as my model FEATURES for my model for two reasons:
From an end-user perspective, I wanted a simple app that requires the user to input only a few types of health data
The five features were considered most important by Random Forest Classifier
Here are the five features:
TimeEat, NUMERIC feature representing the original survey question of “What is the total time (minutes) spent eating and drinking (primary meals during the day)?”
TimeSnack, NUMERIC feature representing the original survey question of “What is the total time (minutes) spent eating and drinking (primary meals during the day)?”
ExerciseFrequency, NUMERIC feature representing the original survey question of_“During the past 7 days, how many times did you participate in any physical activities or exercises for fitness and health such as running, bicycling, working out in a gym, walking for exercise, or playing sports?”_
FastFoodFrequency, NUMERIC feature representing the original survey question of “How many times in the last 7 days did you purchase: prepared food
from a deli, carry-out, delivery food, or fast food?”
GeneralHealth, CATEGORICAL feature representing the original survey question of_“In general, would you say that your physical health was excellent,
very good, good, fair, or poor?”_
Building Classification Models and Their Classification Results
To consider models with high interpretability and predictive power, I examined Logistic Regression (LR) and Random Forest (RF) classifiers, respectively. I setup a pipeline that ran feature scaling and 10-fold cross-validation (CV) on each of the two classifiers. Grid-searching was also performed to find the best hyper-parameters. Finally, model performance was asessed using the (unseen) test set.
For the purpose of app deployment, the entire dataset was used for training. The trained model was embedded in a Python Flask app, which utilizes d3.js sliders as input method.
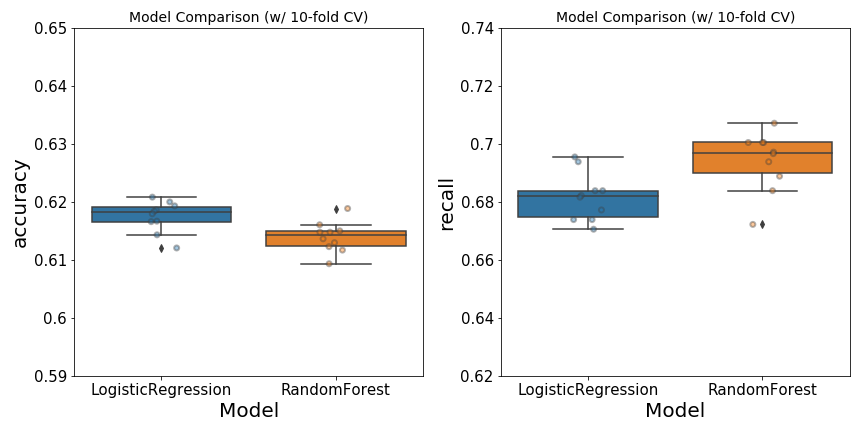
Performance Evaluation. In general, the performance of Logistic Regression (LR) is comparable with that of Random Forest (RF) classfier (Figure 1). The LR model has a slightly higher accuracy than RF. However, the recall score for RF is better than that of LR. The latter is of great importance in healthcare, as it would be costly to misclassify someone who has an obesity-related disease as healthy. For this reason, I chose Random Forest as the classifier used in app deployment.
Figure 1. Performance of Logistic Regression and Random Forest classifiers on the training set. Hyper-parameters used in each model were optimezed using grid-search-CV. Left, the accuracy of each model was computed with 10-fold CV. Right, recall score was also obtained with 10-fold cross-validation. Jittered points on box-and-whiskers reflect scores for each of the ten folds.
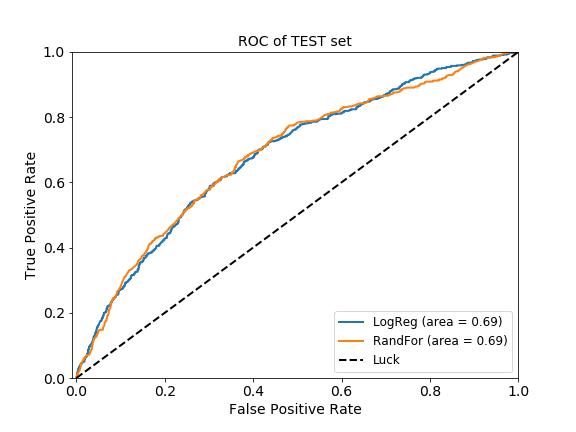
In general, the two models perform similarly on the test set. Similar AUC scores (~0.69) were obtained by LR and RF (Figure 2).
Figure 2. ROC curves of the LR and RF classifiers. Curves were generated with the predicted and the true target values of the test set. Diagonal dashed line indicates random chance.
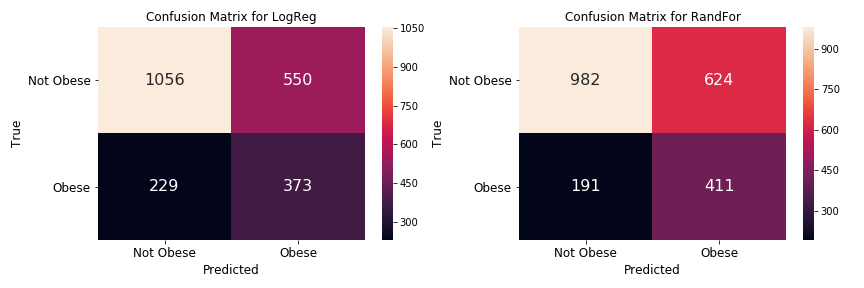
Higher recall score in the RF classifier means that we are better at detecting obesity in people, which potentially means saving more lives! The RF classifier has fewer False Negative (191) than the LR (229), as illustrated in Figure 3. This means, we would have saved additional 32 people by using the RF classifier instead of LR.
Figure 3. Confusion matrices for LR and RF classifiers. These diagrams were generated using true and predicted target values of the test set.
Recovering Model Interpretability. Although the RF classifier is known to be a robust model with high predictive power, it is a “black-box”-like model due to its low interpretability. To recover some of this aspect, I decided to use Local Interpretable Model-agnostic Explainer (LIME). This package allows us to investigate the effect of feature-variation on the prediction result. For instance, a given individual is predicted to be obese by the RF classifier, with P(obese) of 0.59 (left of Figure 4). We could calculate how the P(obese) changes with the increase of a particular feature, or a combination of features. For this subject, the individual did not participate in any type of exercises, i.e. 0exerciseFrequency (right). However, if a physician were to suggest an exercise plan for this individual, such as suggesting 4 exercises a week (i.e., increasing exerciseFrequency from 0 to 4), then the P(obese) would decrease to 0.56, indicating that this person would have lower chances of becoming obese. This type of calculation can be performed for each feature, or any combinations of features, at any increments. LIME outputs the overall effect of feature changes on the prediction probabilities (middle of figure).
Figure 4. Output of LIME on RF predictions on a given individual. Left, prediction probabilities for a given individual. Middle, the average impact of each feature on the probability of being obese, P(obese). This figure is representative of case_ID #001 (i.e., a single observation in the test set).
In conclusion, using RF and LIME together to predict the chances of obesity seems to be an appropriate approach, as this combination provides both predictive power and interpretability.
Future work
Model improvement. Interpretability is an important issue in the healthcare sector, because a physician needs to be able to explain to clients how a particular action/habit may lead to a certain outcome. For this reason, implementing a simple interpretable model like logistic regression would be suitable. So, exploring feature engineering for a logistic model would be one option that I’d like to investigate in the future. In particular, I’d be interested in applying various feature transformations, (especially) because the variables were not normally distributed. I’d like to also see the impact of adding more features to the current model (only 5 were considered at this point). Alternatively, I’d like to explore other combinations of LIME and ensemble models, to get a better predictive power yet maintain some of the explainable aspect.
Collect more data. Currently, only 6 years worth of data are available, and the data span from 2006 to 2008 and from 2014 to 2016. I’d like to collect more data (as they become available) and retrain my model. I’d also be interested in looking at non-survey data from elsewhere, because the current project hinges upon the assumption that the experimental data is reliable. In other words, I had assumed that people who were surveyed would answer those questions accurately. In reality, I’d suspect that there would be some inconsistencies, i.e., people are forgetful, or people may feel apprehensive about sharing private information, etc. Furthermore, the current survey questions were focused on individuals’ habits over the past 7 days, which may not be a representative of a person’s “true” lifestyle. For instance, an obese individual who happened to have started a new diet & exercise routine (during the surveyed week) would have answered these questions in a way that reflects his/her “new” lifestyle, as opposed to the previous one. Lastly, I’d like to try using other metrics that describe obesity better. The target response used for this model is based on BMI, which may not be indicative of obesity. For instance, someone who has a great body mass (e.g., a crossfitter or bodybuilder) is typically considered obese, based on BMI. So playing around with this target measure may give a more insightful outcome.
Predicting NFL Player Salary Based on Early Career Perfomance
Introduction
This project was completed during my third week at Metis data science bootcamp. Based on the curriculum, the focus of this project were web-scraping and linear regression models. Unlike the first project, this one was completed individually, i.e., I had the opportunity to determine the scope of the project and to design a way to collect-, clean-, and analyze the data. To this end, I decided to focus my work on NFL analytics.
Having recently moved to Seattle (for the bootcamp), it was the perfect time for me to see the lives of Seattelites through the eyes of their beloved football team, the Seahawks. This team has demonstrated their field-dominance in recent years, as they achieved a Super Bowl victory (in 2013) with their quarterback, Russell Wilson. Wilson’s rise-to-fame story is a perfect example of the moneyball success. As the 75th-pick overall (3rd round), Wilson was drafted by the Seahawks and was signed to a 4-year contract deal that was worth $2.9 million. With less than 1 million annual salary, he took the Seahawks to Super Bowl twice, brought home the Lombardi once, and broke several franchise records. During this period, many (including myself) contended that Russell Wilson deserved higher salary. However, were there any data that support this intuition? In other words, compared to his peers, was Russell Wilson really underpaid during his early NFL career?
In my attempt to answer this question, I wanted to find the value of a player with respect to their early NFL career performance
Project Description and Approach
Each player that is drafted into the NFL typically gets a 4-year contract deal (1st-round players get a 5th year option). Under this contract, a player is unable to renegotiate his salary, even if he excels beyond the franchise’s expectations. Given a set of performance measures, what would be the “market value” ($$$) of a player, e.g., on their 4th year?
Data Acquisition
The scope of my project was limited to 3 types of offensive positions: quarterbacks (QB), running backs (RB), and wide receivers (WR). My approach in assessing players’ early career performance was to collect data that describe their (1) draft worthiness, (2) their first four years of performance stats, (3) and their 4th year salary. These data were webscraped using beautifulsoup and selenium from pro-football-reference and spotrac. The gruesome details of webscraping and preprocessing are described elsewhere, and the codes are available in my repo. Briefly,
Draft worthiness - represent players’ physique info and NFL combine results. I chose to use these features, to build upon similar studies by others (ref-1, ref-2). The data include players’ name, draft status, draft round, weight, height, and 40-yard dash record (other results were excluded due to missing values). My analysis was limited to players entering the NFL between 2000 and 2014 (Pro-football-reference.com only has records for rookies that enter the league in year 2000 and later).
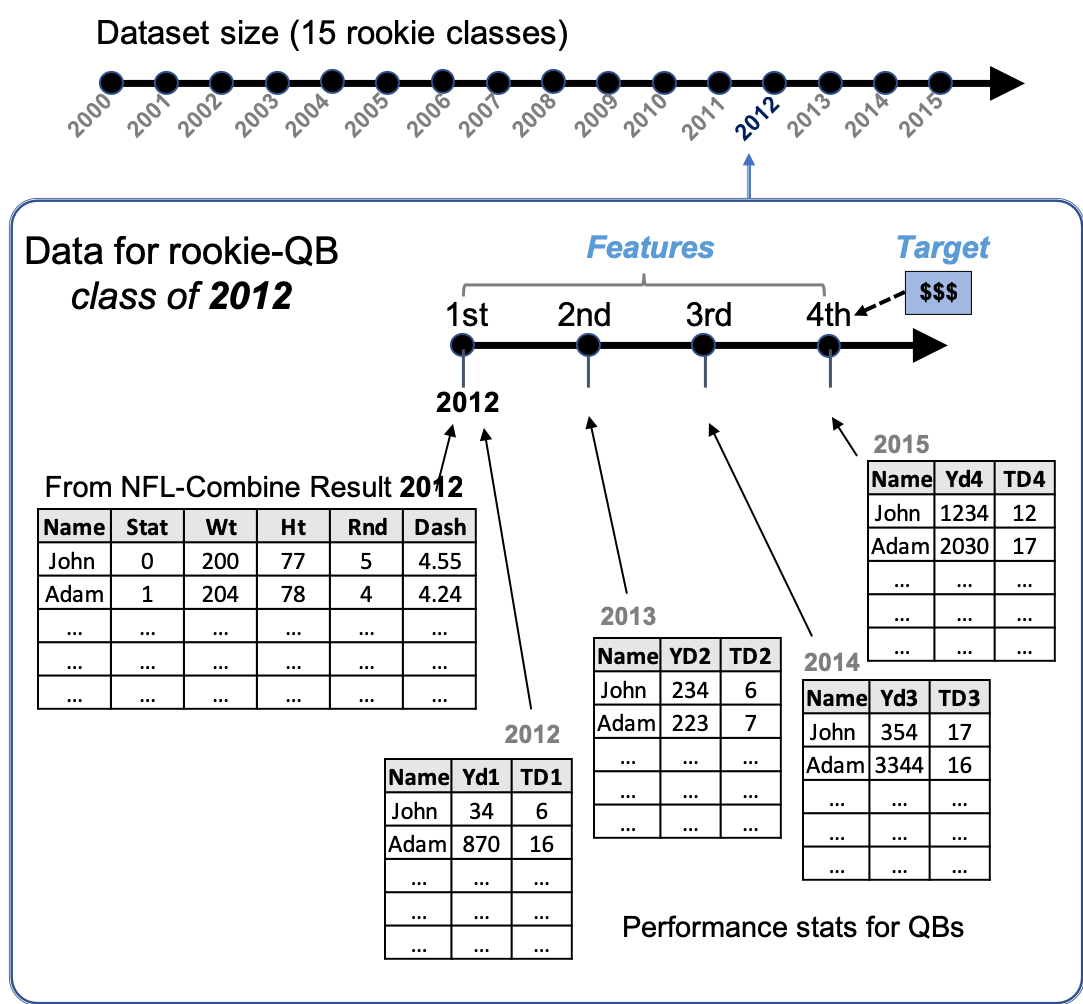
Four years of performance measures - represent position-specific yards (Yds) and touchdowns (TD) accumulated by each player within the first 4 years of his career. Web-scraping and preparing the datasets were very time-consuming. For a given rookie QB that entered the NFL in 2012, the total passing Yds and TDs for each of the 4 years were scraped from different pages (seeFigure 1). Additionally, these stats had to also be collected for each the 3 different positions. Passing, rushing and receiving Yds (or TD) were extracted for QB, RB, and WR, respectively.
Figure 1. Workflow of data acquisition. Inset illustrates data collection required for a single class of rookie QB entering the NFL in 2012.
The 4th year base salary of each player - was used as the target value for my model (seeFigure 1). I chose to use this 4th-year information, so that I could target “active” players (i.e., those still playing in NFL at their 4th-year) like Russell Wilson. I collected players’ salaries over the 15-year period of 2003-2015. I also recalculated each year’s salary using the annual inflation rate, to reflect a value that is relevant today, 2018.
Data Wrangling and Feature Engineering
With the workflow described above, I ended up collecting 45 dataframes (i.e., 15 per position), representing 15 years of performance data. However, I couldn’t directly combine all of these dataframes into one table, as the stats correspond to different positions. For instance, the value of rushing Yards may not be identical with passing Yds, nor receiving Yds. So, I decided to normalize the weight of Yds and TDs for each of these different positions using a standard Yahoo fantasy football point system:
For RB, 1 point for every 10 rushing yards, and 6 points for every TD
For WR, 1 point for every 10 receiving yards, and 6 points for every TD
For QB, 1 point for every 10 passing yards, and 4 points for every TD
After transforming players’ Yds & TDs into points, I merged the 45 dataframes together into a single table. Categorical features (such as position and draft status) were one-hot encoded, and one of each of these category-columns was dropped, to avoid the dummy variable trap. Some features were also tranformed using the log1p or box-cox or Yeo-Johnson method. Many of these features were largely skewed to the right, as rookie players often make little impact in their first 4 years of NFL career.
Regression Models and Analysis
After cleaning my dataset and removing “non-active” players (i.e., those who didn’t get paid on their 4th year), I ended up with 356 rows of players and 11 features. (By the way, it was quite remarkable to see that almost 70% of new players entering the NFL didn’t last 4 years). The 11 features I included in my model were draft status, draft round, weight, height, 40-yard dash, 4 years of performance points (i.e., Year1, Year2, Year3, and Year4), and positions (RB or WR) (Figure 2).
Figure 2. A sample observation from the dataframe containing 11 features. Player names are excluded in the regression models.
Prior to building a regression model, I split the dataframe into training (80%) and testing (20%) sets. With the training set, I built a pipeline that runs feature scaling and 10-fold CV on LinearRegression, Ridge, Lasso, ElasticNet. (Regularization parameters for Ridge, Lasso and ElasticNet were obtained using LassoCV, RidgeCV, and ElasticNetCV). For comparison, I also included tree-based regressors:RandomForestRegressor, DecisionTreeRegressor, andBaggingRegressor, without any hyperparametric tuning.
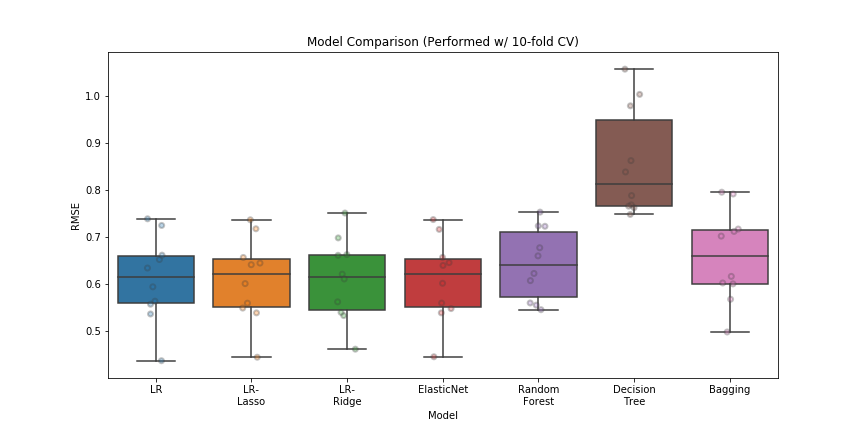
The result of 10-fold CV on each of the regressors was not as optimal as I had hoped. All linear regression models showed comparable results (Figure 3) with root-mean-squared error (RMSE) of ~0.61, lower than tree-based methods (RMSE~0.64-0.85). Also, r-squared values for linear regressors were abput ~0.21, higher than the those of tree-based regressors, ~0.12.
Figure 3. Model-performance on the training set, based on 10-fold CV. Jittered points reflect errors on each fold.
I decided to use the simple linear regression model, without regularizations, to predict players’ salary on the test set. I chose to use the simplest interpretable model, as it be useful for NFL managers in assessing their players.
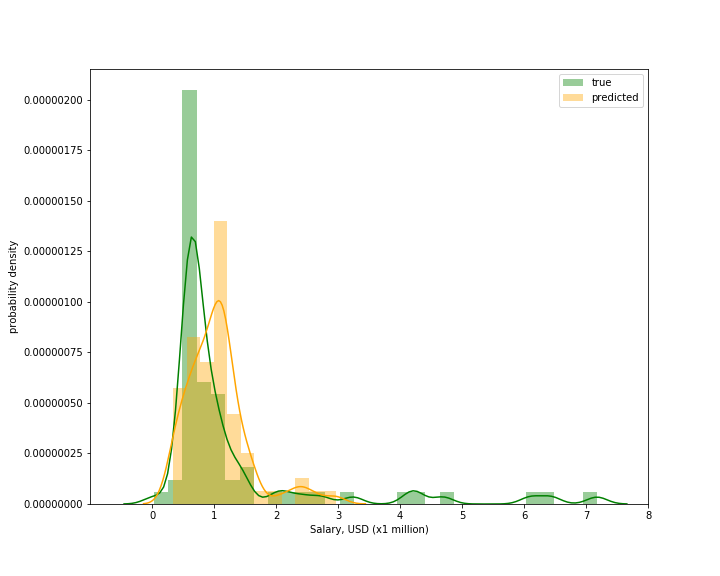
The linear regression model is fairly effective in predicting players’ salaries (Figure 4). The prediction (orange line) seems to capture the bulk distribution of players’ salary ranging from 0 to ~2 million USD. However, it shows weaker predictive power for high-income players receiving ~4-8 million USD. This model’s tendency to predict lower salary is most likely influenced by the skewed distribution of features (described earlier). Although various transformations were applied, many of those features had outliers at or near zeros (data not shown). Overall, the curent model has an (RMSE) error of ~1 million USD, which is considered substantial for (rookie) players.
Figure 4. Predicted and true target values in the test set. Predicted- and true salary are illustrated using kernel density estimation, which estimates the probability density function. The horizontal (x-axis) represents salary distribution in the test set, whereas vertical (y-axis) shows the probability density of a given salary.
Once I optimized my linear regressor on the training set, I used it to predict Russell Wilson’s salary, given his performance stats and NFL combine results. The result suggests that an NFL player with his stats should receive ~2.6 million USD, which is higher than Wilson’s actual pay (<1 million/year). Even when the error is considered (~1 million), Wilson’s value should be around 1.6 million USD. So, I would contend that indeed the Seahawks got a very good deal by signing Wilson with a 4-year contract for only ~3 million USD. In other words, given his performance, Russell Wilson could (should) have been paid more that he received.
Summary and Future Work
As it turns out, this classic “moneyball” problem (though successful in MLB) may not be as trivial to achieve in the NFL. At the moment, my model only considers features that are related directly to the individuals, i.e., their performance stats and NFL combine results. However, I believe there are other factors that could affect the value of an NFL player and provide higher predictive power. For example, I would have wanted to include variables that represent a player’s opportunity to play in a game (e.g., playing time per game, number of injured players in the depth chart, etc.).
In addition, I would have wanted to create different regression models for the 3 offensive positions and to use a bigger dataset to train each model. Currently, only one model was used to predict salaries for the 3 types of offensive players, QB, RB, and WR, due to limited number of training datapoints (356 total players). It is important to note that the 4-year-survival rate for NFL players is pretty low, ~30-40%. Not too many players actually last 4 years and longer. Also, pro-football-reference.com only keeps NFL-Combine stats for players entering the NFL from year 2000 and later, which further limits the number of available datapoints. In essence, the challenge of building robust models from limited number of observations remains difficult to accomplish, even in the NFL.
At the end of this NFL analytics project, I felt like I learned so much in building an end-to-end data science pipeline. Through this process, I learned how to web-scrape data from multiple sources, create python scripts to streamline the data preparation process, build simple predictive models, and extract informative insights from them. I can’t wait to work on my next project, so stay tuned for my next installment.
Thanks for reading. A more detailed explanation of my codes is available on my repo. Any helpful comments and suggestions are appreciated.
Attribution
This project was inspired by the work of Ka Hou Sio and Jason SA, who investigated the valuation of NBA and MLB players at METIS.